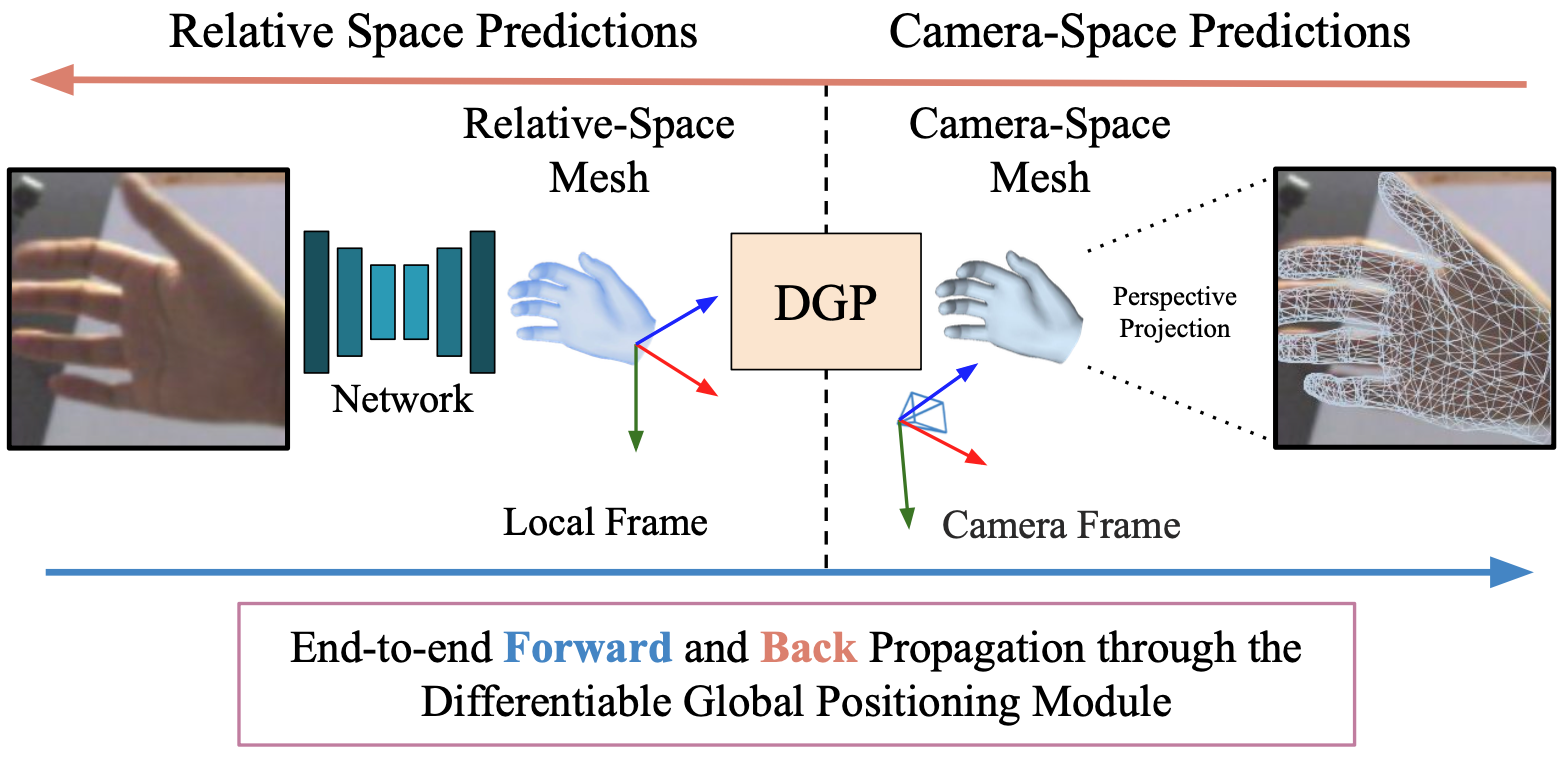
Predicting camera-space hand meshes from single RGB images is crucial for enabling realistic hand interactions in 3D virtual and augmented worlds. Previous work typically divided the task into two stages: given a cropped image of the hand, predict meshes in relative coordinates, followed by lifting these predictions into camera space in a separate and independent stage, often resulting in the loss of valuable contextual and scale information. To prevent the loss of these cues, we propose unifying these two stages into an end-to-end solution that addresses the 2D-3D correspondence problem. This solution enables back-propagation from camera space outputs to the rest of the network through a new differentiable global positioning module. We also introduce an image rectification step that harmonizes both the training dataset and the input image as if they were acquired with the same camera, helping to alleviate the inherent scale-depth ambiguity of the problem. We validate the effectiveness of our framework in evaluations against several baselines and state-of-the-art approaches across three public benchmarks.
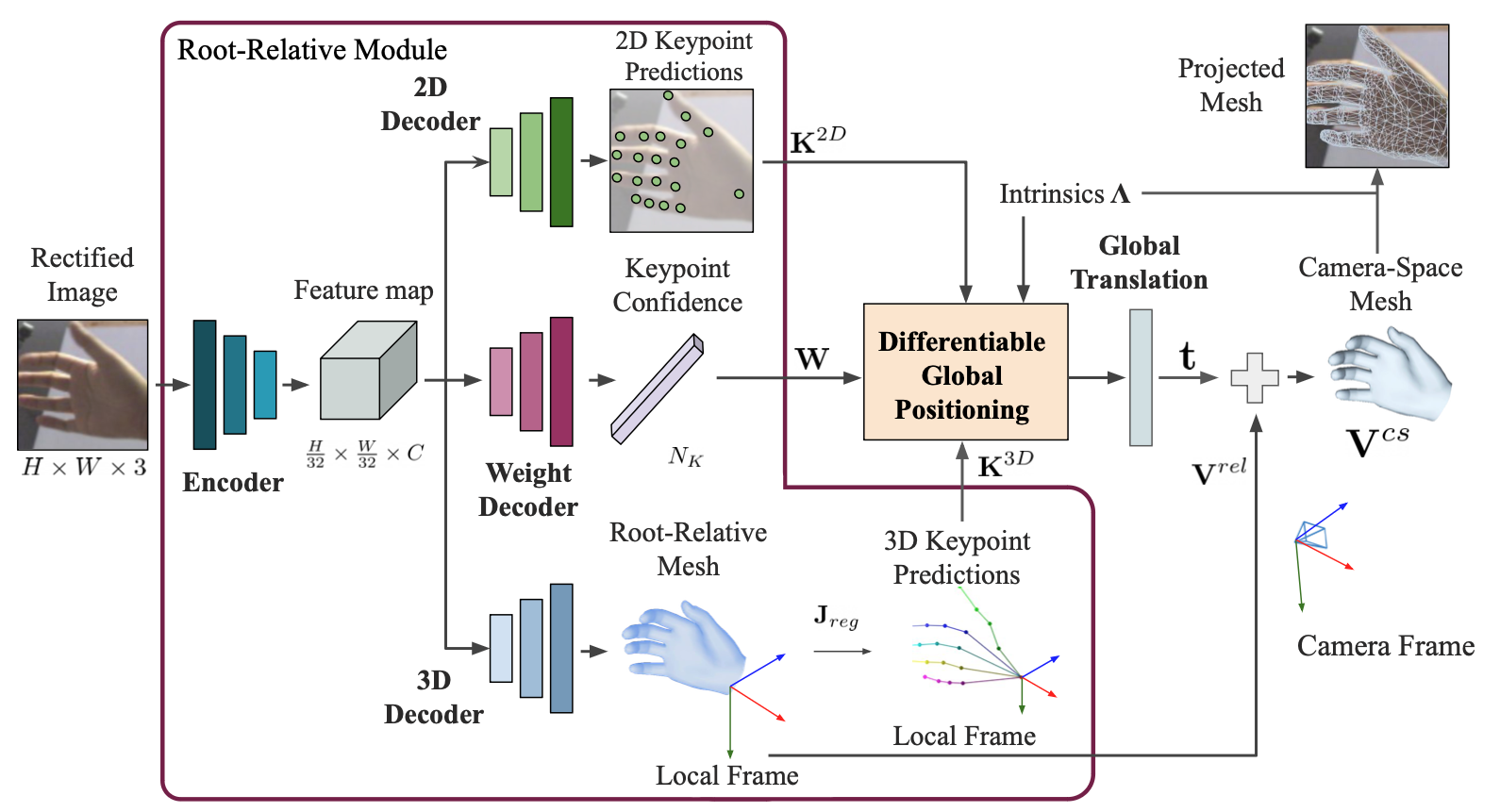
We propose an end-to-end approach that simultaneously learns root-relative meshes and the 3D lifting function using a Differentiable Global Positioning (DGP) module. This method enables direct backpropagation of gradients from camera space outputs to 2D-3D correspondences, enhancing the integration with hand mesh prediction networks that predict 2D keypoints and root-relative 3D hand meshes. Additionally, we introduce a rectification step to address 2D-to-3D depth and scale ambiguity, improving camera-space predictions at a slight cost to relative-space predictions.
Qualitative results on FreiHAND, HO3D-v2, Human3.6M datasets and online images:

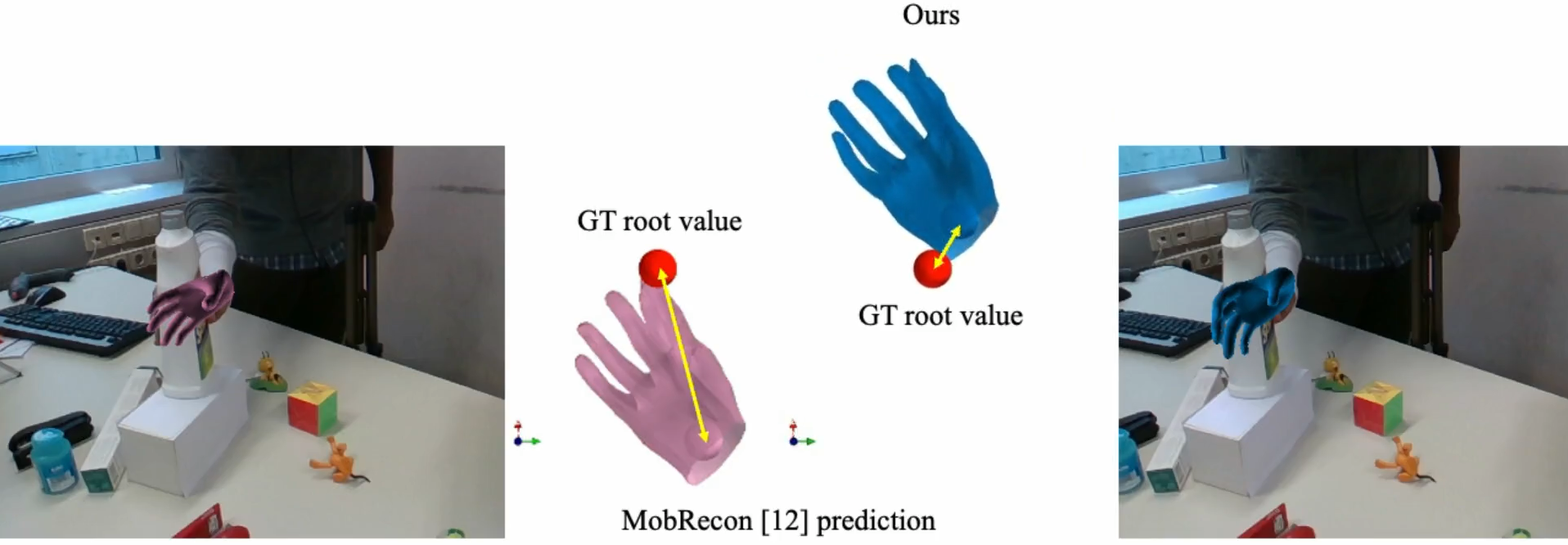
Comparison with MobRecon. HandDGP predicts more accurate 3D root values and hand meshes:
Video results on HO3D-v2 dataset:
3D positioning visualization:

If you find this work useful for your research, please consider citing our paper:
@inproceedings{handdgp2024,
title={{HandDGP}: Camera-Space Hand Mesh Prediction with Differentiable Global Positioning},
author={Valassakis, Eugene and Garcia-Hernando, Guillermo},
booktitle={ECCV},
year={2024}}